
데이터 분석에서 통계학의 중요한 역할은, 퍼짐(산포, dispersion)이 있는 데이터에 대해 설명이나 예측을 하는 것입니다. (24)
이러한 데이터 퍼짐은 대상이 가진 성질이나 관계성의 본모습을 감추고, 정확하게 파악할 수 없도록 합니다. 데이터 퍼짐에 의해 실제로는 약의 효과가 없는데도 불구하고 효과가 있다고 판단하는 오류나, 거꾸로 효과가 있음에도 효과가 없다고 판단하는 오류가 일어나기도 합니다. 통계학은 이러한 데이터 퍼짐을 '불확실성'이라 평가하고, 통계학의 목적인 '대상의 설명과 예측'을 수행합니다. (24)
모집단에서 추출한 표본은 유한한 개수의 요소를 포함합니다. 통계학에서는 표본에 포함된 요소의 개수를 표본크기(sample size)라 부르며, 보통 알파벳 n으로 나타냅니다. 예를 들어 표본으로 30개를 추출했다면, n=30이라 표기합니다. (44)
1장에서 설명했듯이 통계학(특히 추론통계)에서는 확률룐이 중요합니다. 이는 통계학이, 관찰한 데이터를 모집단에서 확률적으로 발생한 값으로 상정하고, 데이터 자체나 데이터의 배후에 있는 법칙을 이해하고자 하는 시도이기 때문입니다. (69)
앞의 예에서 변수 X={붉은 구슬, 흰 구슬}이라 하면, P(X=붉은구슬)=4/5, P(X=흰 구슬)=1/5의 식으로 표현할 수 있습니다. 여기서 X와 같이 확률이 달라지는 변수를, 확률변수라 부릅니다. 그리고 확률변수가 실제로 취하는 값(여기서는 붉은 구슬 또는 흰 구슬)을 실현값이라 합니다. (70-71)
추론통계는 모집단의 일부인 표본에서 모집단의 성질을 추정하고자 합니다. 그러나 모집단은 직접 관측할 수 없고 이해하기도 어려운 대상이기에, 표본으로 추정하는 일 역시 어려울 듯합니다. 이에 그림 3.4.4와 같이 현실 세계의 모집단을 수학 세계의 확률분포로 가정하고, 표본 데이터는 그 확률분포에서 생성된 실현값인 것으로 가정하여 분석을 진행합니다. 이렇게 함으로써 '모집단과 표본 데이터'처럼 다루기 어려운 대상이 '확률분포와 그 실현값'처럼 다룰 수 있는 대상으로 치환되는 것입니다. (73)

모집단과 표본의 관계를 확률변수와 실현값의 관계로 바꾸어 보면 "얻은 표본으로 모집단을 추정한다."라는 원래 목표를 "얻은 실현값으로 이 값을 발생시킨 확률분포를 추정한다."라는 목표로 바꾸어 말할 수 있습니다. (91)

(92)

모집단의 평균 μ나 표준편차σ 등은 고정된 값이지만, 모집단분포에서 얻은 표본 x₁, x₂, …, xₙ을 모집단에서 무작위로 추출하여, 이 표본(데이터)에서 모집단평균 μ를 추정하는 것으로 생각해 가겠습니다. (99)
이처럼 표본은 모집단의 성질과 정확히 일치하지 않고, 확률오차를 수반합니다. 그러므로 표본으로 모집단의 성질을 정확히 알아맞히기는 불가능합니다. 그러나 여기서 포기하지 않고 이 오차에 대해 파고들어 생각하는 것이 중요하며, 이런 면에서 통계학은 '오차의 학문'이라 해도 과언이 아닙니다. (101)
주사위 예를 보면, 표본평균 x̄ 도 확률변수입니다. 왜냐하면 x̄=(x₁+…+xₙ)/n이고, 각 요소 xᵢ 가 확률변수이기 때문입니다. 표본오차 = x̄- μ도 μ라는 정수를 뺀 것뿐이므로 마찬가지로 확률변수입니다. 그로부터 표본오차의 확률분포를 짐작할 수 있습니다. 이렇듯 표본오차의 확률분포를 알면 어느 정도 크기의 오차가, 어느 정도의 확률로 나타나는지를 알 수 있게 됩니다. (103)
3장에서 설명한 정규분포의 성질을 떠올려 봅시다. 정규분포에서는 평균 μ 와 표준편차 σ (또는 분산) 2가지의 파라미터를 알면 분포 형태와 위치가 하나로 결정되고, 따라서 각 값이 어떤 확률로 나타날지를 알아낼 수 있습니다. (104)
결론은 아주 간단한데, 표본오차 = x̄- μ 의 분포는 모집단의 표준편차 σ 와 표본크기 n 등 2개의 값만 정해지면 알 수 있다는 것입니다. 이 σ / √n 을 표준오차(standard error)라 합니다. (108)
(128)
여기서 중요한 것은, 표본크기 n이 커지면 p값은 작아지므로 검출하고자 하는 효과크기를 사전에 설정하고 표본크기 n을 설계해야 한다는 점입니다. 간혹 표본크기 n을 사전에 설계하지 않은 관찰 데이터로부터 표본크기 n이 매우 큰, 예를 들어 n=10,000인 데이터를 얻을 때가 있습니다. 이러한 데이터로 가설검정을 시행하면 앞서 이야기한 것처럼 아주 작은 차이로도 p값이 작아져, 통계적으로 유의미한 차이를 검출하게 됩니다. (270-271)
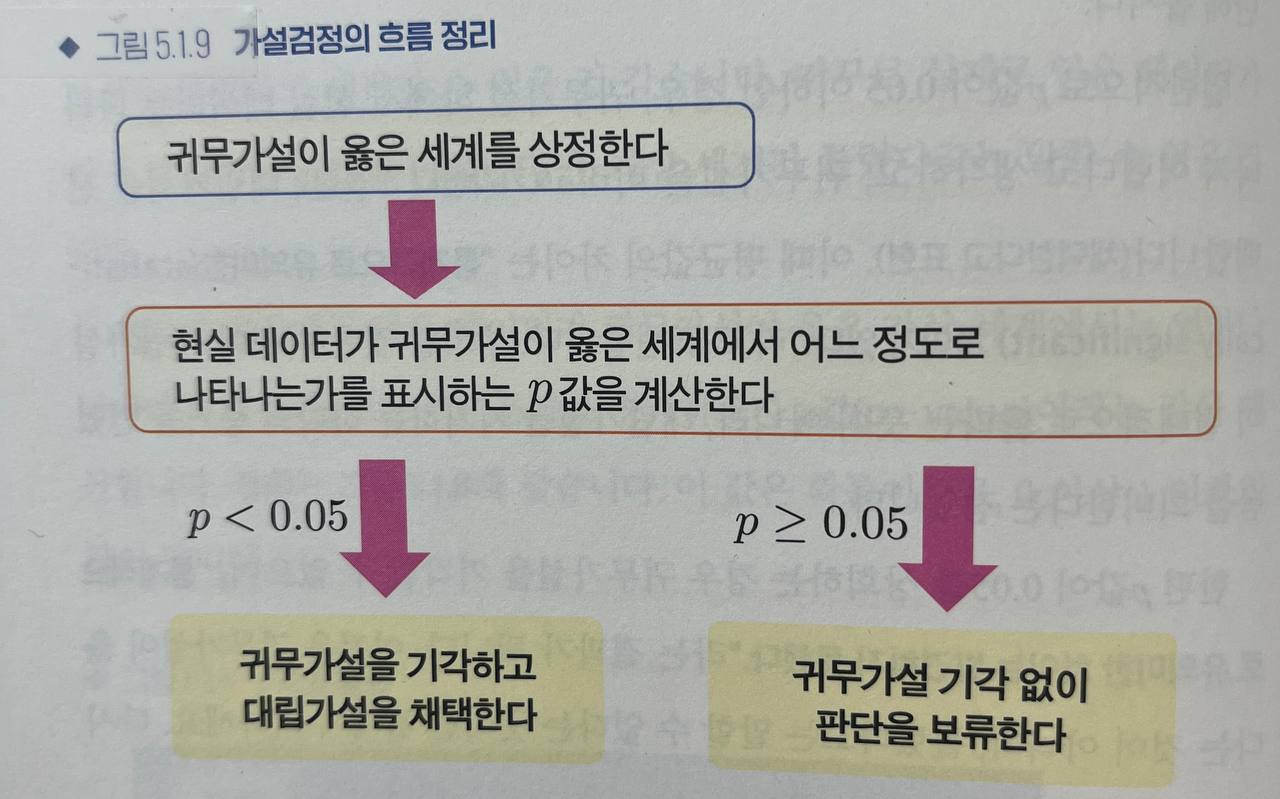
가설검정 구조에서는 p<0.05을 얻었을 때 귀무가설을 기각하고 대립가설을 재택하는 것이 흐름이었습니다. 이와 달리 p≥0.05일 때는 "통계적으로 유의미한 차이가 없다(발견되지 않았다)"라고 표현하는데, 이는 귀무가설을 채택하는 것이 아니라 판단을 보류한다는 뜻입니다. 가설검정에서 귀무가설과 대립가설은 대등한 관계가 아니므로, 귀무가설을 지지할 수는 없기 때문입니다. (274)
(286-287)


다시 말해, 우리는 모든 것을 상정할 수 없기 때문에, '현상의 실제 모습=실제 모형'을 만들기란 불가능하다고 할 수 있습니다. 그러나 실제 모형이 아닐지언정 현상을 적절하게 기술할 수 있는 모형이라면 이해에 도움이 되며, 예측이나 통제라는 목적도 달성할 수 있습니다. (371)
'서재 > 비소설' 카테고리의 다른 글
| [불안] 알랭 드 보통. 은행나무. (0) | 2026.04.07 |
|---|---|
| [통계학 리스타트] 이다 야스유키. 비즈니스맵. (1) | 2026.03.03 |
| [요리를 한다는 것] 최강록. 클. (2) | 2026.01.09 |
| [사는 곳, 바뀔 곳, 오를 곳] 전형진. 한국경제신문. (1) | 2026.01.09 |
| [그것도 괜찮겠네] 이사카 코타로. 웅진지식하우스. (0) | 2025.09.21 |